客服热线:010-65538878


银行历史数据集中系统的大数据技术实践
来源:《金融电子化》杂志
目前Hadoop/HBase广泛应用于各类具有大数据需求的企业,尤其是互联网企业,实践已证明其对大数据处理的适用性。银行历史数据系统具有的“大数据”特征,作者探索了采用Hadoop/HBase实现历史数据集中系统。
目前银行历史数据系统主要采用关系型数据库进行数据存储,如Oracle RAC方式,但此方式具有诸多限定,例如数据量积压到一定值后,将极大影响联机查询效率;只适合存储结构化数据,难以满足对半结构化和非结构化历史数据的处理;成本较高,一套系统性能完善的历史系统仅硬件成本将超过千万。基于银行历史数据系统具有的“大数据”特征,我们探索采用当前广泛应用的大数据技术解决方案,基于Hadoop/HBase的技术架构,给出技术结果、分析关键技术及技术特性。
一、Hadoop/HBase简介
Hadoop是Apache软件基金会的一个开源项目,目的是为用户提供一个能够对大量数据进行分布式处理的软件框架,具有可靠、高效、可伸缩等特点。HBase则是APache的Hadoop的子项目,在Hadoop之上提供高可靠性、高性能、可伸缩的分布式数据库系统。不同于一般的关系数据库,利用HBase技术可在廉价PC服务器上搭建起大规模结构化数据库集群系统。
HDFS是Hadoop分布式文件系统,为HBase提供了高可靠性的底层存储支持。MaPReduce是Hadoop任务调度管理模块,为HBase提供了高性能的计算能力。Zookeeper是Hadoop的分布式协调服务,为HBase提供了稳定服务和容错机制。
此外,开源社区提供基于Hadoop的支持工具,如:Pig是一个基于Hadoop的大规模数据分析平台,Hive是基于Hadoop的一个数据仓库工具,使得在HBase上进行数据统计处理变得非常简单。Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变得非常方便。
Ambari是一种基于Web的、支持Apache Hadoop集群的供应、管理和监控的工具。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、Hbase、Zookeeper、Sqoop等集中管理。
目前Hadoop/HBase广泛应用于各类具有大数据需求的企业,尤其是互联网企业,如Facebook、Twitter、ebay、雅虎、阿里、百度、华为、国内部分电信运营商等公司,国外摩根、花旗等银行都已开展具体应用。其中,阿里、国内部分电信运营商都已经采用Hadoop/HBase实现对历史数据(如话费单、购买交易记录)的查询等功能。阿里Hadoop/HBase集群节点数目将近5000个,实践已证明其对大数据处理的适用性。
二、系统架构
基于Hadoop/HBase历史数据集中系统逻辑结构如图1所示。
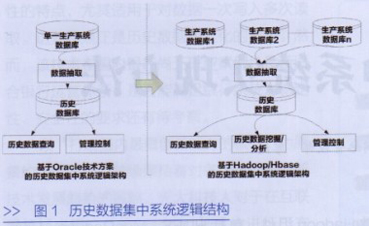
1.历史数据获取。历史数据通过数据抽取系统,从相关生产数据库中抽取所需数据,为不影响关键业务系统性能,可以通过灾备线路将数据导入历史数据库中。相对于基于Oracle RAC的技术方案,新技术方案由于技术架构的横向可扩展性,在不影响系统性能的条件下,可以同时对接多个生产数据库,实现历史数据的集中处理。
2.历史数据查询。历史数据查询模块实现联机交易查询,根据查询时间段,将查询结果反馈给前台用户。相对于基于Oracle RAC的技术方案,新技术方案由于具备大数据量的处理能力,不但能够提高查询效率,而且历史联机查询的时间范围能随着处理数据量扩展,例如从以前5年历史查询扩展到查询30年的历史数据。
3.历史数据挖掘分析。相对于Oracle RAC的技术方案,新技术架构由于具有天然大数据技术特性,可以做到综合多种生产数据来源,从海量历史数据中进一步挖掘分析出所需信息,例如用户行为分析等,以优化相关金融服务产品,提高用户体验、防范风险。
从图2物理结构上看,相对于基于Oracle RAC的技术方案,新技术方案在展示层、应用服务层改动较小,在数据资源层改变较大,去除了磁盘阵列要求,数据全部存储在HBase域服务器本地硬盘上。新技术方案中,数据存储层,各服务器作用如下。
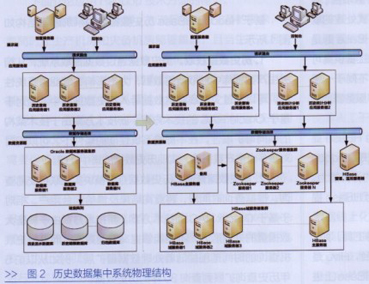
Zookeeper服务器集群:为HBase提供了稳定服务和容错机制,为应用提供数据库配置信息、命名、分布式协调服务。
HBase主服务器:实现HBase集群初始化,负责数据表格、域分配管理;负责管理域服务器的负载均衡,调整域分布。数据资源层只有一台在线使用的HBase主服务器,但没有单点问题,HBase中可以启动多个HBase主服务,通过Zookeeper保证总有一个HBase主服务运行。
HBase域服务器集群:负责响应应用的数据I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。所存储的数据以文件形式保存在本地盘中。
HBase管理、监控服务器:基于Ambari工具,为运维人员提供HBase集群的管理和监控功能。
三、技术特性
采用Hadoop/HBase实现历史数据集中系统,能够满足海量历史数据高效的联机查询需求,并通过Hive/Pig等工具实现数据挖掘分析功能,具备如下技术特性。
高可靠性:Hadoop/HBase维护多个数据副本,确保能够针对失败的节点重新分布处理,其备份恢复机制以及计算任务监控机制保证了分布式处理的可靠性。高扩展性:Hadoop/HBase具备存储和计算可扩展性,为处理海量数据,可以很方便地将集群扩展到数以干计节点规模,处理规模能够达到PB级。高效性:Hadoop/HBase以并行的方式工作,处理速度高效。经济性:基于Hadoop/HBase的大数据处理都运行在廉价的PC服务器上,无需购置昂贵的小/大型机以及磁盘阵列设备。
值得注意的是,新技术除具备以上技术优点外,其具体应用中也存在一定技术风险。首先,HBase不是传统关系型数据库管理系统,需要应用开发人员抛弃原有数据库系统设计方法,重新掌握NoSQL等新技术知识。其次,Hadoop/HBase是全新的技术,目前国内精通此技术的人员较少,尚无专业技术服务支持公司,需要银行自我培养人才队伍。最后,Hadoop/HBase采用开源方式发行,相关自动化运维辅助工具较少,要维护管理好一个大规模Hadoop/HBase集群,需要投入一定数量的技术人员。

